Ö oder =?iso-8859-1?Q?=D6?=
Umlaute in E-Mails
Johann Haider
Electronic Mail gehört heute zu den wichtigsten Anwendungen,
die über das Internet abgewickelt werden. Praktisch wird nur mehr
das SMTP Protokoll verwendet, andere Formen der Mailübertragung führen
bestenfalls noch ein Nischendasein innerhalb geschlossener Benutzergruppen.
Das Protokoll ist nicht in einem Guss entstanden, sondern wurde im Laufe
der Zeit den Erfordernissen angepasst. Deshalb kann es zu Problemen
bei der Darstellung kommen, wenn Sender und Empfänger sich nicht auf
den gleichen Protokollstandard einigen können.
Prinzip des SMTP Protokolls
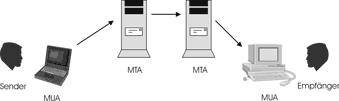
Der Sender erstellt seine Nachricht mit Hilfe des Mail User Agent (MUA),
dieser reicht sie an den zugeordneten MTA (Mail Transfer Agent) weiter.
Über eine Kette von weiteren MTAs wird die Nachricht bis zum MTA des
Zielrechners geschickt, wo die Mailbox des Empfängers liegt. Die Übertragung
zum MUA des Empfängers wird nicht über das SMTP Protokoll abgewickelt
[14, 15].
Nachrichtenformat
Eine Nachricht besteht aus dem Message Header, in dem für Menschen
und Rechner lesbare Informationen stehen, und dem Message Body, das ist
die vom Absender erstellte Nachricht.
Der Header besteht aus so genannten
Fields, einige der bekannteren sind:
From:
Absender
To:
Empfänger
Subject:
Betreff
Message-ID:
Eindeutige Identifikation der Nachricht
Alle Felder bis auf Message-ID sind vom Protokoll betrachtet optional.
(Die Nachricht kommt auch dann an, wenn kein To:
Feld existiert, da die Zieladresse auch außerhalb der Nachricht
übertragen wird.)
Historischer Rückblick
Im Jahr 1977 wurde in einem Dokument über Internet Text Messages ein
Verfahren zum Übertragen von Nachrichten veröffentlicht. Aus
diesem entwickelte sich das SMTP Protokoll, das im Jahr 1982 in den Dokumenten
RFC 821 bzw. RFC 822 in die heute verwendete Form gebracht wurde. Auf Grund
der Wurzeln des Internet in US amerikanischen Militär- und Universitätseinrichtungen
wurde für die Übertragung der Nachricht nur der ASCII Zeichensatz
vorgesehen.
Die Möglichkeit zur Übermittlung von Nachrichten,
die einen nationalen Zeichensatz verwenden, wurde nicht berücksichtigt.
Trotzdem gab es bald eine Reihe von nicht standardisierten Erweiterungen
der Software von verschiedenen Herstellern, sodass innerhalb geschlossener
Gruppen die Verwendung von nationalen Zeichensätzen möglich war
(Schweden, Japan).
8-Bit Zeichensätze waren zu dieser Zeit auf MS-DOS
bzw. Macintosh Rechnern vorhanden, nicht aber auf den für die Internet-Kommunikation
verwendeten Unix Systemen. Für verschiedene Sprachen lieferten die
Hersteller der als Eingabegeräte verwendeten Terminals nationale Zeichensätze,
die durch die Zweitbelegung von wenig verwendeten Sonderzeichen entstehen
und in nationalen Normen bzw. später durch ISO 646 genormt wurden.
In den 80er Jahren wurde durch die ISO auch eine 8-Bit Zeichensatzfamilie
genormt, die wesentlich auf dem Multinational Character Set (MCS) der Fa.
Digital beruhte und heute unter dem Namen der Norm ISO 8859 bekannt ist.
Von diesem Zeichensatz gibt es mittlerweile 15 Varianten, wobei ISO 8859-1
(Westeuropäische Sprachen) bei uns am gebräuchlichsten ist. Der
unter Windows gebräuchliche so genannte ANSI Zeichensatz stimmt glücklicherweise
im Bereich der druckbaren Zeichen mit ISO-8859-1 überein.
Tabelle ISO 8859-1 (PDF)
Die leeren Positionen sind für nicht-druckbare Steuerzeichen reserviert. Der Zeichensatz ISO 8859-15 verwendet die Position 164 für das € -Symbol (im Windows-Zeichensatz liegt das Euro-Symbol auf Position 128).
Um 1990 begann sich die Internet Engineering Task Force (IETF) damit
zu befassen, wie die gerade neu genormten oder vorgeschlagenen 8- und 16-Bit
Zeichensätze nach ISO 8859 bzw. Unicode [5, 6] in E-Mails verwendet
werden sollten, bzw. wie der Transport dieser Daten verlustfrei erfolgen
kann. Im Speziellen befassten sich verschiedene IETF Komitees:
-
eine Erweiterung für eine 8-Bit Datenübertragung zu definieren,
die kompatibel mit RFC 821 ist. Das Ergebnis war das Dokument RFC 1425
vom Februar 1993, dessen letzte Revision als RFC 1869 verfügbar ist
[7, 8].
-
eine Erweiterung von RFC 822 zu definieren, die es erlaubt, dem Empfänger
die im Text verwendete Codierung der Zeichen mitzuteilen, sodass die Lesbarkeit
auch dann gegeben ist, wenn kein reiner ASCII Code verwendet wird. Dieses
Dokument wurde 1992 als RFC 1341 verabschiedet, der aktuelle Stand ist
in RFC 2045 bis RFC 2049 zu finden [9, 10, 11, 12, 13] und wird allgemein
als MIME-Standard bezeichnet.
Zu Beginn der 90er Jahre herrschte allgemein die Ansicht, dass in absehbarer
Zeit ein Umstieg auf OSI X.400 Mailprotokolle erfolgen werde und das SMTP
Protokoll nur mehr für einen begrenzten Zeitraum notwendig wäre.
Auch an der TU Wien wurde im Jahr 1994 ein X.400 fähiges Mailgateway
installiert. Da der Support des Herstellers nicht befriedigend war und
kein Bedarf für ein Multiprotokoll-Mailgateway mehr bestand, wurde
diese Software 1998 durch die aktuelle Release eines nur SMTP-fähigen
Programmes ersetzt.
Übertragung von Mails mit Umlauten
Der MIME Standard schreibt vor, dass im Mailheader folgende Deklarationen
des Inhalts enthalten sein müssen, wenn die Nachricht standardkonform
sein soll.
Z. B.
Mime Version: 1.0
Content-type: text/plain; charset=iso-8859-1
Content-transfer-encoding: quoted-printable
oder
Mime Version: 1.0
Content-type: text/plain; charset=iso-8859-1
Content-transfer-encoding: 8bit
Content-type
beschreibt den Aufbau der Nachricht an sich, welcher vom Autor der Nachricht
vorgegeben wird. Content-transfer-encoding
beschreibt, wie die Nachricht während der Übertragung verpackt
wird, damit sie nicht verstümmelt wird. Wenn im Verbindungspfad zwischen
Sender und Empfänger mehrere Stationen vorhanden sind, kann es vorkommen,
dass die Nachricht ein oder mehrmals zwischen beiden Content-transfer-encoding
Varianten konvertiert wird.
Probleme bei der Darstellung von Umlauten
Grundsätzlich sollten keine Probleme auftreten, wenn alle beteiligten
Programme standardkonform sind. Der Mailclient des Senders und des Empfängers
müssen dem MIME Standard entsprechende Mails senden bzw. lesen können.
In [16] ist eine Liste von Programmen angegeben, die Umlaute verarbeiten
können: auf der Windows-Plattform u. a. MS Outlook, Netscape Communicator,
Pegasus Mail; auf Unix-Rechnern pine und mutt. Alle MTA auf dem Weg vom
Sender zum Empfänger müssen entweder RFC 821 konform sein oder
dem Standard RFC 1652 entsprechen. Wenn das nicht der Fall ist, besteht
die Gefahr, dass eine Nachricht verstümmelt beim Empfänger ankommt,
wenn eine 8-Bit Nachricht auf dem Weg einen Rechner passiert hat, der nur
7-Bit Daten verarbeiten kann.
Sollte einmal ein Problem auftreten ("Das
hat bis jetzt immer funktioniert"), kann man durch Analyse der Mailheader
zeigen, wo das Problem liegt. Dazu ist es notwendig, den vollständigen
Mailheader zu sehen, nicht nur die Auszüge, die die Mailprogramme
standardmäßig bieten. Sollte kein Mailclient bei der Hand sein,
der die vollständige Darstellung der Mailheader erlaubt, ist es auch
möglich, die Mails ohne Umweg über einen Mailclient direkt vom
Pop Account abzurufen [15].
Codierung der Mailheader
In einem Mailheader dürfen nur Zeichen aus dem US-ASCII Zeichensatz
vorkommen. Analog zur Kodierung des Message Body wird in RFC 2047 festgelegt,
wie Mailheader aufbereitet werden müssen, wenn sie andere als Zeichen
aus dem US-ASCII Zeichensatz enthalten. Solche Zeichen treten insbesondere
in den vom Absender eingegebenen Teilen des Header (z. B. Display Namen,
Subject) auf.
Beispiel aus RFC 2047 [11]:
From: =?ISO-8859-1?Q?Olle_J=E4rnefors?= <ojarnef@admin.kth.se>
To: ietf-822@dimacs.rutgers.edu, ojarnef@admin.kth.se
Subject: Time for ISO 10646?
Wenn beide Partner mit Mailprogrammen
arbeiten, die dem Standard entsprechen, werden diese Umschreibungen für
den Benutzer niemals sichtbar. Erst wenn eine solche Nachricht mit einem
Programm weiterverarbeitet wird, das mit dem MIME Standard nichts anfangen
kann, wird direkt der kodierte Text angezeigt. Werden Modifikationen in
den kodierten Teilen vorgenommen, muss die Änderung mit großer
Sorgfalt durchgeführt werden, damit das Ergebnis wie erwartet ausfällt.
Ausblick
Da die 8-Bit Codes nicht ausreichen, um Texte aller Weltsprachen darzustellen,
wurde von Industrieseite Unicode und von der ISO die Norm 10646 geschaffen.
Beide Organisationen haben sich mittlerweile so weit geeinigt, dass für
die praktische Anwendung beide Normen gleichgesetzt werden können.
In der Version 3 ist Unicode ein 16-Bit Code, in dem 49194 Zeichen definiert
sind, darunter europäische Alphabete, Hebräisch, Arabisch, asiatiasche
Schriftzeichen, mathematisch-technische Symbole, weiters wurden (für
uns) exotische Sprachen und Braille aufgenommen [17, 18, 19, 23].
Die untersten 128 Zeichen sind mit dem ASCII Code identisch. Wenn ein
Text hauptsächlich aus ASCII Zeichen besteht, würde eine direkte
Speicherung in 16-Bit Unicode das Volumen durch Nullbytes auf das Doppelte
vergrößern. Die Nullbytes können auch bei der Übertragung
von Texten Probleme machen, deshalb wurde zum Austausch von Daten (z. B.
per E-Mail) die Codierung UTF-8 entwickelt, die alle Zeichen im ASCII Zeichensatz
unverändert lässt [20, 21, 22]. In diesem Sinne wäre auch
das Versenden von Mails, in deren Header steht:
Content-type: text-plain; charset=utf-8
Content-transfer-encoding: quoted-printable
für die existierende Serverinfrastruktur kein Problem, allerdings
gibt es wenige (PC-)Mailclients1,
die diese Codierung unterstützen. Wenn wir in unseren E-Mails das
€ verwenden wollen, werden wir diese Unterstützung benötigen.
Referenzen
[1] ASCII, "USA Code
for Information Interchange", United States of America Standards Institute,
X3.4, 1968.
[2] Crocker,
D., "Standard for the Format of ARPA Internet Text Messages", RFC 822,
Department of Electrical Engineering, University of Delaware, August 1982.
[3] Postel, J.,
"Simple Mail Transfer Protocol", STD 10, RFC 821, USC/Information Sciences
Institute, August 1982.
[4] Borenstein,
N., and N. Freed, "MIME (Multipurpose Internet Mail Extensions): Mechanisms
for Specifying and Describing the Format of Internet Message Bodies", RFC
1341, Bellcore, Innosoft, June 1992.
[5] International
Standard - Information Processing - 8-bit Single-Byte Coded Graphic Character
Sets
Part 1: Latin Alphabet No. 1, ISO
8859-1:1998, 1st ed.
Part 2: Latin Alphabet No. 2, ISO
8859-2:1999, 1st ed.
Part 3: Latin Alphabet No. 3, ISO
8859-3:1999, 1st ed.
Part 4: Latin Alphabet No. 4, ISO
8859-4:1998, 1st ed.
Part 5: Latin/Cyrillic Alphabet,
ISO 8859-5:1999, 2nd ed.
Part 6: Latin/Arabic Alphabet,
ISO 8859-6:1999, 1st ed.
Part 7: Latin/Greek Alphabet, ISO
8859-7:1987, 1st ed.
Part 8: Latin/Hebrew Alphabet,
ISO 8859-8:1999, 1st ed.
Part 9: Latin Alphabet No. 5, ISO/IEC
8859-9:1999, 2nd ed.
International Standard - Information
Technology - 8-bit Single-Byte Coded Graphic Character Sets
Part 10: Latin Alphabet No. 6,
ISO/IEC 8859-10:1998, 2nd ed.
International Standard - Information
Technology - 8-bit Single-Byte Coded Graphic Character Sets
Part 13: Latin Alphabet No. 7,
ISO/IEC 8859-13:1998, 1st ed.
International Standard - Information
Technology - 8-bit Single-Byte Coded Graphic Character Sets
Part 14: Latin Alphabet No. 8 (Celtic),
ISO/IEC 8859-14:1998, 1st ed.
International Standard - Information
Technology - 8-bit Single-Byte Coded Graphic Character Sets
Part 15: Latin Alphabet No. 9,
ISO/IEC 8859-15:1999, 1st ed.
[6] ISO/IEC 10646-1:1993(E),
"Information technology - Universal Multiple-Octet Coded Character
Set (UCS) - Part 1: Architecture and Basic Multilingual Plane", JTC1/SC2,
1993.
[7] Klensin,
J., Freed, N., Rose, M., Stefferud, E. and D. Crocker, "SMTP Service Extensions",
STD 10, RFC 1869, November 1995.
[8] Klensin,
J., (WG Chair), Freed, N., (Editor), Rose, M., Stefferud, E., and Crocker,
D., "SMTP Service Extension for 8bit-MIME transport", RFC 1652,
United Nations University, Innosoft, Dover Beach Consulting, Inc., Network
Management Associates, Inc., The Branch Office, March 1994.
[9] Freed, N., and N. Borenstein, "Multipurpose
Internet Mail Extensions (MIME) Part One: Format of Internet Message Bodies",
RFC 2045, Innosoft, First Virtual Holdings, November 1996.
[10] Freed, N., and N. Borenstein,
"Multipurpose Internet Mail Extensions (MIME) Part Two: Media Types", RFC
2046, Innosoft, First Virtual Holdings, November 1996.
[11] Moore, K., "Multipurpose Internet
Mail Extensions (MIME) Part Three: Representation of Non-ASCII Text in
Internet Message Headers", RFC 2047, University of Tennessee, November
1996.
[12] Freed, N., Klensin, J., and J.
Postel, "Multipurpose Internet Mail Extensions (MIME) Part Four: MIME Registration
Procedures", RFC 2048, Innosoft, MCI, ISI, November 1996.
[13] Freed, N. and N. Borenstein, "Multipurpose
Internet Mail Extensions (MIME) Part Five: Conformance Criteria and Examples",
RFC 2049 (this document), Innosoft, First Virtual Holdings, November 1996.
[14] Crispin, M., "Internet Message
Access Protocol - Version 4", RFC 1730, University of Washington, December
1994.
[15] Myers, J. & Rose, M., "Post
Office Protocol - Version 3.", RFC 1939, Carnegie Mellon University, May
1996.
[16] Christof Awater, "Umlaute in E-Mail
und Netnews", FAQ für de.newusers.questions URL: http://www.westfalen.de/paefken/de.newusers/umlaute-faq.txt
[17] The Unicode Consortium, The Unicode
Standard, Version 3.0 Reading, MA, Addison-Wesley Deve-lopers Press, 2000.
ISBN 0-201-61633-5.
[18] New in Version 3.0
http://www.unicode.org/unicode/standard/versions/Unicode3.0.html
[19] Unicode Blocks
http://www.unicode.org/Public/UNIDATA/Blocks.txt
[20] Yergeau, Francois, "UTF-8, a
transformation format of ISO 10646", RFC 2279, Alis Technologies Montreal,
January 1998.
[21] Czyborra, Roman, Unicode Übersicht,
http://www.czyborra.com, Dissertation in Arbeit, Berlin 2000.
[22] Lohner, Martin, "Stand der Unicode-Entwicklung",
ix 10/2000, Verlag Heinz Heise, Hannover 2000.
[23] Zagler, Wolfgang, "Kommunikationstechnik
für behinderte und alte Menschen", Vorlesungsskriptum TU Wien, 2000,
Beschreibung von ISO/DIS 11 548-2.
1 Bei einem stichprobenartigen Test erlaubte nur Microsoft Outlook das Erstellen und Verschicken von E-Mails mit €-Symbol.
Zum Inhaltsverzeichnis,
ZIDline 4, Dezember 2000